The Ensenso Way
Ensenso - pioneer in stereo vision for industrial applications

Ensenso - pioneer in stereo vision for industrial applications

Ensenso cameras operate using Stereo Vision, which imitates the human vision. Two cameras acquire images from the same scene from two different positions.
Although the cameras see the same scene content, there are different object positions according to the cameras projection rays. Special matching algorithms compare the two images, search for corresponding points and visualize all point displacements in a Disparity Map.
Knowing the distance and viewing angle of the cameras in addition to the lens focal length, the Ensenso software converts these disparities in length units using the triangulation principle. So the 3D coordinates of each image pixel could be determined. The result is a 3D point cloud, which is the foundation for further applications based on 3D object information.

The matching process during the image comparison is based on contrast- and brightness graduations of the sensor pixels. So the Stereo Vision quality directly depends on the scene’s light condition and object surface textures. Finding and calculating coordinates of corresponding points on less textured or reflecting surfaces is very difficult. The disparity cannot be uniquely determined. The result is an incomplete depth information of the scene.
Ensenso cameras improve the classic Stereo Vision principle by additional techniques to achieve a higher quality depth information and more precise measurement results. As a consequence Stereo Vision can be used in a wider range of applications.

A light-intensive projector produces a high-contrast texture on the object surface by using a pattern mask, even under difficult light conditions. The projected texture supplements the weak or non-existent object surface structure.
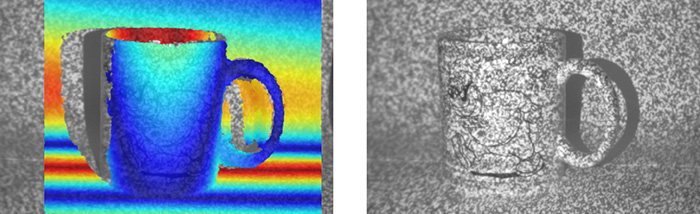
Therefore this principle is also called “Projected Texture Stereo Vision”. The result is a more detailed disparity map and a more complete and homogeneous depth information of the scene.
The FlexView technology can further improve the detail level of the disparity map of static scenes. The position of the pattern mask in the projection rays can be translated in small steps by a mechanical system using a piezoelectric actuator. The result is a varying texture on the object surface. Acquiring multiple image pairs with different textures of the same object scene produce a lot more image points. The resolution increases. The matching algorithm calculates significantly improved disparity maps by using all captured image pairs.
As a consequence of the texture displacement which produces additional structure information on glossy, dark or reflecting surfaces, the resolution and also the robustness of the resulting data will increase. A lot of processing algorithms benefit from the higher resolution and the lower noise. FlexView reduces post processing steps of the point cloud and further 3D processing time.
Passive versus active stereo vision with different flexview settings
Color-coded height map comparing different capture settings: other vendors (left) versus Ensenso technology (right)
Ensenso offers cameras with and without FlexView technology. Each solution is optimized and adapted to particular applications. The object movement plays a decisive role in this respect.
Cameras without FlexView and respectively with FlexView1 technology produce a high-contrast texture by using a random dot-pattern. It allows calculating depth information very fast even with only one image pair. Both camera variants are equally suitable for application with moving objects.
Using static objects FlexView1 cameras additionally benefit from algorithms, which produce a higher resolution combining multiple image pairs acquired with translated dot-pattern. With only 3 to 5 image pairs, the X-, Y- and Z-resolution can be doubled. But with each additional image pair the acquisition and processing will increase. With approximately 8 image pairs the resulting quality doesn’t increase any further with FlexView1.
Cameras implementing FlexView2 technology use a specially designed pattern-mask with appropriate algorithms able to double the resolution in X-, Y- and Z-direction of static objects compared with FlexView1.
Constraints: Due to the special pattern, the optimization is effective only with at least 5 image pairs.
|
Random dot-pattern used as projector mask for cameras without FlexView respectively with FlexView 1. Optimized for single shot data.
|
Additional brightness gradients in the FlexView 2 pattern support the appropriate algorithms by calculating objects depth information with at least 5 image pairs. These brightness gradients reduce the pattern’s effectiveness in single shot data. |
The PatchMatch stereo matching algorithm improves stereo matching run times compared to other algorithms while at the same time giving you infinite measurement range. Pre-trained parameter sets reduce the number of user-adjustable stereo matching settings to a minimum and provide high quality data in all situations right away.
The video below shows how the point cloud emerges from random data when using PatchMatch.
These include essential cookies that are necessary for the operation of the site, as well as others that are used only for anonymous statistical purposes, for comfort settings or to display personalized content. You can decide for yourself which categories you want to allow. Please note that based on your settings, not all functions of the website may be available.
Contents
I. Information about us as the controlling entity
II Rights of users and data subjects
III. Information on data processing
Contact enquiries / contact option
Online job applications / publication of job adverts
Website hosting www.optonic.com
General linking to profiles with third-party providers
YouTube on the Optonic website
It is possible to use our website without providing personal data. Different regulations may apply to the use of individual services on our website, which are explained separately below. Your personal data (e.g. name, address, email, telephone number, etc.) will only be processed by us in accordance with the provisions of the applicable data protection law (see below). In general, Optonic GmbH does not handle personal data. Data is personal if it can be clearly assigned to a specific natural person.
Personal data (hereinafter mostly referred to as ‘data’) is only processed by us to the extent necessary and for the purpose of providing a functional and user-friendly website, including its content and the services offered there.
According to Article 4(1) of Regulation (EU) 2016/679, i.e. the General Data Protection Regulation (hereinafter referred to as ‘GDPR’), ‘processing’ means any operation or set of operations which is performed on personal data or on sets of personal data, whether or not by automated means, such as collection, recording, organisation, structuring, storage, adaptation or alteration, retrieval, consultation, use, disclosure by transmission, dissemination or otherwise making available, alignment or combination, restriction, erasure or destruction.
With the following privacy policy, we provide information in particular about the type, scope, purpose, duration and legal basis of the processing of personal data, insofar as we decide either alone or together with others on the purposes and means of processing. In addition, we inform you below about the third-party components we use for optimisation purposes and to increase the quality of use, insofar as third parties process data on their own responsibility.
Our privacy policy is structured as follows
I. Information about us as the controller
II. rights of users and data subjects
III. Information on data processing
The responsible provider of this website in terms of data protection law is
Optonic GmbH
Represented by the managing directors:
Rainer Voigt, Johannes Schade, Rainer Voigt, sr.
Zollhallenstraße 11
79106 Freiburg im Breisgau
Phone: +49 761 15436-0
Email: info[AT]optonic.com
Contact person for data protection matters at Optonic GmbH:
René Purwin - Data Protection Coordinator
rene.purwin[AT]optonic.com
Optonic GmbH has appointed an independent, external data protection officer to monitor Optonic's compliance with the applicable laws and regulations on data protection (GDPR, European and German laws, BDSG). As a visitor to our website, you can contact the data protection officer if you have the impression that we are violating these laws and regulations or if you have any questions about our handling of personal data.
Contact details of the data protection officer:
PROLIANCE GmbH
Leopoldstr. 21
80802 Munich, Germany
datenschutzbeauftragter@datenschutzexperte.de
When contacting the data protection officer, please state the company to which your enquiry relates. Please refrain from enclosing sensitive information such as a copy of your ID with your enquiry.
With regard to the data processing described in more detail below, users and data subjects have the right
In addition, the provider is obliged to inform all recipients to whom data has been disclosed by the provider of any correction or deletion of data or the restriction of processing that takes place on the basis of Articles 16, 17 para. 1, 18 GDPR. However, this obligation does not apply if this notification is impossible or involves a disproportionate effort. Notwithstanding this, the user has a right to information about these recipients.
Users and data subjects also have the right to object to the future processing of data concerning them in accordance with Art. 21 GDPR, provided that the data is processed by the provider in accordance with Art. 6 para. 1 lit. f) GDPR. In particular, an objection to data processing for the purpose of direct advertising is permitted.
Your data processed when using our website will be deleted or blocked as soon as the purpose of storage no longer applies, the deletion of the data does not conflict with any statutory retention obligations and no other information is provided below on individual processing methods.
The provider (Strato AG, see below) uses a cookie manager to obtain consent for the use of technically unnecessary cookies on the website.
When the website is accessed, a cookie with the settings information is stored on the user's end device so that the query regarding consent does not have to be made on a subsequent visit.
The cookie is required to obtain the user's legally compliant consent.
The user can prevent or stop the installation of cookies by changing the settings in their browser.
a) Session cookies/session cookies
We use so-called cookies on our website. Cookies are small text files or other storage technologies that are placed and stored on your end device by the Internet browser you use. These cookies are used to process certain information from you, such as your browser or location data or your IP address, on an individual basis.
This processing makes our website more user-friendly, effective and secure, as the processing enables, for example, the reproduction of our website in different languages or the offer of a shopping basket function.
The legal basis for this processing is Art. 6 para. 1 lit. b) GDPR, insofar as these cookies process data for contract initiation or contract fulfilment.
If the processing does not serve to initiate or fulfil a contract, our legitimate interest lies in improving the functionality of our website. The legal basis in this case is Art. 6 para. 1 lit. f) GDPR.
These session cookies are deleted when you close your Internet browser.
b) Third-party cookies
Our website may also use cookies from partner companies with whom we work for the purposes of advertising, analysing or the functionalities of our website.
Please refer to the following information for details, in particular the purposes and legal basis for processing such third-party cookies.
c) Removal option
You can prevent or restrict the installation of cookies by changing the settings of your Internet browser. You can also delete cookies that have already been saved at any time. However, the steps and measures required for this depend on the specific Internet browser you are using. If you have any questions, please use the help function or documentation of your Internet browser or contact its manufacturer or support. In the case of so-called Flash cookies, however, processing cannot be prevented via the browser settings. Instead, you must change the settings of your Flash player. The steps and measures required for this also depend on the specific Flash player you are using. If you have any questions, please also use the help function or documentation of your Flash player or contact the manufacturer or user support. For security reasons, we advise against using a Flash player.
However, if you prevent or restrict the installation of cookies, this may mean that not all functions of our website can be used to their full extent.
If you contact us via contact form or email, the data you provide will be used to process your enquiry. The provision of the data is necessary for processing and answering your enquiry - without it we cannot answer your enquiry or can only answer it to a limited extent.
The legal basis for this processing is Art. 6 para. 1 lit. b) GDPR.
Your data will be deleted if your enquiry has been conclusively answered and the deletion does not conflict with any statutory retention obligations, such as in the case of any subsequent contract processing.
If you register for our free newsletter, the data requested from you for this purpose, i.e. your email address and - optionally - your name and address, will be transmitted to us. At the same time, we store the IP address of the Internet connection from which you access our website as well as the date and time of your registration. As part of the further registration process, we will obtain your consent to send you the newsletter, describe the content in detail and refer you to this privacy policy. We use the data collected in this process exclusively for sending the newsletter - in particular, it is therefore not passed on to third parties.
The legal basis for this is Art. 6 para. 1 lit. a) GDPR.
You can revoke your consent to receive the newsletter at any time with effect for the future in accordance with Art. 7 para. 3 GDPR. All you have to do is, inform us of your cancellation or click on the unsubscribe link contained in every newsletter.
We offer you the opportunity to apply for a job with us via our website. For these digital applications, we collect and process your applicant and application data electronically to handle the application process.
The legal basis for this processing is Section 26 (1) sentence 1 BDSG in conjunction with Art. 88 (1) GDPR. Art. 88 para. 1 GDPR.
If an employment contract is concluded after the application procedure, we will store the data you submitted during the application in your personnel file for the purpose of the usual organisational and administrative process - of course in compliance with further legal obligations.
The legal basis for this processing is also Section 26 para. 1 sentence 1 BDSG in conjunction with Art. 88 para. 1 GDPR. Art. 88 para. 1 GDPR.
If an application is rejected, we automatically delete the data transmitted to us within a maximum of two months after notification of the rejection. However, the data will not be deleted if the data requires longer storage of up to four months or until the conclusion of legal proceedings due to legal provisions, e.g. due to the burden of proof under the AGG.
In this case, the legal basis is Art. 6 para. 1 lit. f) GDPR and Section 24 para. 1 no. 2 BDSG. Our legitimate interest lies in legal defence or enforcement.
If you expressly consent to your data being stored for a longer period of time, e.g. for your inclusion in a database of applicants or interested parties, the data will be processed further on the basis of your consent. The legal basis is then Art. 6 para. 1 lit. a) GDPR. However, you can of course revoke your consent at any time in accordance with Art. 7 para. 3 GDPR by making a declaration to us with effect for the future.
For technical reasons, in particular to ensure a secure and stable Internet presence, data is transmitted to us or to our web space provider by your Internet browser. With these so-called server log files, the type and version of your Internet browser, the operating system, the website from which you have switched to our Internet presence (referrer URL), the website(s) of our Internet presence that you visit, the date and time of the respective access and the IP address of the Internet connection from which our Internet presence is used are collected, among other things.
The data collected in this way is stored temporarily, but not together with other data about you.
This storage takes place on the legal basis of Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the improvement, stability, functionality and security of our website.
The data will be deleted after seven days at the latest, unless further storage is required for evidence purposes. Otherwise, the data is excluded from deletion in whole or in part until an incident has been finally clarified.
This website is hosted by the German provider Strato. Strato AG is a processor within the meaning of Art. 28 of the GDPR and has concluded a corresponding ‘order processing contract’ (AVV) with us: https://www.strato.de/agb/avv/
Contact Strato: https://www.strato.de/impressum/
Strato AG, Otto-Ostrowski-Str. 7, 10249 Berlin, Germany
Strato hosts all websites, including ours, exclusively on web servers in Germany, so that the GDPR applies without restriction. Details on the handling of personal data can be found in Strato AG's privacy policy: https://www.strato.de/datenschutz/
The legal basis for data processing by Strato AG results from Art. 6 I lit. a GDPR and further paragraphs of the GDPR.
The data transmitted by you to utilise our range of goods and/or services is processed by us for the purpose of contract processing and is required in this respect. Conclusion and fulfilment of the contract are not possible without the provision of your data.
The legal basis for the processing is Art. 6 para. 1 lit. b) GDPR.
We delete the data once the contract has been fully processed, but must observe the retention periods under tax and commercial law.
As part of the contract processing, we pass on your data to the transport company commissioned with the delivery of goods or to the financial service provider, insofar as the transfer is necessary for the delivery of goods or for payment purposes.
The legal basis for the transfer of data is then Art. 6 para. 1 lit. b) GDPR.
We maintain an online presence on LinkedIn to present our company and our services and to communicate with customers/prospects. LinkedIn is a service of LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Ireland, a subsidiary of LinkedIn Corporation, 1000 W. Maude Avenue, Sunnyvale, CA 94085, USA.
In this respect, we would like to point out that there is a possibility that user data may be processed outside the European Union, in particular in the USA. This may result in increased risks for users in that, for example, subsequent access to user data may be made more difficult. We also have no access to this user data. The access option lies exclusively with LinkedIn.
You can find LinkedIn's privacy policy at
https://www.linkedin.com/legal/privacy-policy
We maintain an online presence on YouTube to present our company and our services and to communicate with customers/prospects. YouTube is a service of Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, a subsidiary of Google LLC, 1600 Amphitheatre Parkway, Mountain View, CA 94043 USA.
In this respect, we would like to point out that there is a possibility that user data may be processed outside the European Union, in particular in the USA. This may result in increased risks for users in that, for example, subsequent access to user data may be made more difficult. We also have no access to this user data. The access option lies exclusively with YouTube.
You can find YouTube's privacy policy at
https://policies.google.com/privacy
The provider uses a link on the website to the social networks listed below.
The legal basis for this is Art. 6 para. 1 lit. f GDPR. The provider has a legitimate interest in improving the quality of use of the website.
The plugins are integrated via a linked graphic. Only by clicking on the corresponding graphic is the user redirected to the service of the respective social network.
Once the customer has been redirected, the respective network collects information about the user. This is initially data such as IP address, date, time and page visited. If the user is logged into their user account on the respective network during this time, the network operator may be able to assign the information collected about the user's specific visit to the user's personal account. If the user interacts via a ‘Share’ button of the respective network, this information can be stored in the user's personal user account and published if necessary. If the user wants to prevent the collected information from being directly assigned to their user account, the user must log out before clicking on the graphic. It is also possible to configure the respective user account accordingly.
The following social networks are linked by the provider:
We use Google Analytics on our website. This is a web analysis service provided by Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as ‘Google’.
The Google Analytics service is used to analyse the usage behaviour of our website. The legal basis is Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the analysis, optimisation and economic operation of our website.
Usage and user-related information, such as IP address, location, time or frequency of visits to our website, is transmitted to a Google server in the USA and stored there. However, we use Google Analytics with the so-called anonymisation function. This function allows Google to truncate the IP address within the EU or EEA.
The data collected in this way is in turn used by Google to provide us with an analysis of the visit to our website and the usage activities there. This data can also be used to provide other services related to the use of our website and the use of the Internet.
Google states that it will not associate your IP address with any other data. In addition, Google keeps under:
https://www.google.com/intl/de/policies/privacy/partners
provides further data protection information for you, for example on the options for preventing the use of data.
In addition, Google offers at
https://tools.google.com/dlpage/gaoptout?hl=de
a so-called deactivation add-on along with further information on this. This add-on can be installed with the most common Internet browsers and offers you further control over the data that Google collects when you visit our website. The add-on informs the JavaScript (ga.js) of Google Analytics that information about your visit to our website should not be transmitted to Google Analytics. However, this does not prevent information from being transmitted to us or to other web analysis services. You can of course also find out whether and which other web analysis services we use in this privacy policy.
We use Google Maps on our website to display our location and to provide directions. This is a service provided by Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as ‘Google’.
In order to enable the display of certain fonts on our website, a connection to the Google server in the USA is established when our website is accessed.
If you call up the Google Maps component integrated into our website, Google stores a cookie on your end device via your Internet browser. Your user settings and data are processed in order to display our location and provide directions. We cannot rule out the possibility that Google uses servers in the USA.
If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in optimising the functionality of our website.
The connection to Google established in this way enables Google to determine from which website your enquiry has been sent and to which IP address the directions are to be transmitted.
If you do not agree to this processing, you have the option of preventing the installation of cookies by making the appropriate settings in your Internet browser. Details on this can be found above under ‘Cookies’.
In addition, the use of Google Maps and the information obtained via Google Maps is governed by the Google Terms of Use https://policies.google.com/terms?gl=DE&hl=de and the Terms and Conditions for Google Maps https://www.google.com/intl/de_de/help/terms_maps.html.
In addition, Google offers at
https://adssettings.google.com/authenticated
https://policies.google.com/privacy
for further information.
We use “Vimeo” on our website to display videos. This is a service provided by Vimeo, LL C, 555 West 18 th Street, New York, New York 10011, USA, hereinafter referred to as “Vimeo”.
Some of the user data is processed on Vimeo servers in the USA.
If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in improving the quality of our website.
If you visit a page of our website in which a video is embedded, a connection to the Vimeo servers in the USA is established to display the video. For technical reasons, it is necessary for Vimeo to process your IP address. In addition, the date and time of your visit to our website are also recorded.
If you are logged in to Vimeo at the same time as you visit one of our websites in which a Vimeo video is embedded, Vimeo may assign the information collected in this way to your personal user account there. If you wish to prevent this, you must either log out of Vimeo before visiting our website or configure your Vimeo user account accordingly.
Vimeo uses the web analysis service Google Analytics for the purpose of functionality and usage analysis. Google Analytics stores cookies on your end device via your Internet browser and sends information about the use of our Internet pages in which a Vimeo video is embedded to Google. It cannot be ruled out that Google will process this information in the USA.
If you do not agree to this processing, you have the option of preventing the installation of cookies by making the appropriate settings in your Internet browser. Details on this can be found above under “Cookies”.
The legal basis is Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the quality improvement of our website and in the legitimate interest of Vimeo to statistically analyze user behavior for optimization and marketing purposes.
Vimeo offers under
for further information on the collection and use of data and on your rights and options for protecting your privacy.
We use YouTube on our website. This is a video portal of Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as “YouTube”.
We use YouTube in connection with the “extended data protection mode” function in order to be able to show you videos. If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in improving the quality of our website. According to YouTube, the “Enhanced Privacy Mode” function means that the data described in more detail below is only transmitted to the YouTube server when you actually start a video.
Without this “extended data protection mode”, a connection to the YouTube server in the USA is established as soon as you access one of our web pages on which a YouTube video is embedded.
This connection is necessary in order to be able to display the respective video on our website via your Internet browser. In the course of this, YouTube will at least record and process your IP address, the date and time and the website you have visited. In addition, a connection is established to Google's “DoubleClick” advertising network.
If you are logged in to YouTube at the same time, YouTube will assign the connection information to your YouTube account. If you wish to prevent this, you must either log out of YouTube before visiting our website or make the appropriate settings in your YouTube user account.
For the purpose of functionality and analysis of user behavior, YouTube permanently stores cookies on your end device via your Internet browser. If you do not agree to this processing, you have the option of preventing the storage of cookies by changing the settings in your Internet browser. You can find more information on this above under “Cookies”.
Google provides further information about the collection and use of data as well as your rights and protection options in this regard in the privacy policy available at
https://policies.google.com/privacy
If you subscribe to our company's newsletter, the data in the respective input mask will be transmitted to the controller. Subscription to our newsletter takes place in a so-called double opt-in procedure. This means that after registering, you will receive an email asking you to confirm your registration. This confirmation is necessary so that no-one can register with other people's email addresses. When registering for the newsletter, the user's IP address and the date and time of registration are stored. This serves to prevent misuse of the services or the email address of the person concerned. The data is not passed on to third parties. An exception is made if there is a legal obligation to pass on the data. The data is used exclusively for sending the newsletter. Subscription to the newsletter can be terminated by the data subject at any time. Consent to the storage of personal data can also be revoked at any time. There is a corresponding link for this purpose in every newsletter. The legal basis for the processing of data after registration for the newsletter by the user is Art. 6 para. 1 lit. a) GDPR if the user has given consent. The legal basis for sending the newsletter as a result of the sale of goods or services is Section 7 (3) UWG
Description and purpose: We use rapidmail to send newsletters. The provider is rapidmail GmbH, Wentzingerstraße 21, 79106 Freiburg, Germany. Among other things, rapidmail is used to organize and analyse the sending of newsletters. The data you enter for the purpose of subscribing to the newsletter is stored on rapidmail's servers in Germany. If you do not wish to be analyzed by rapidmail, you must unsubscribe from the newsletter. For this purpose, we provide a corresponding link in every newsletter message. For the purpose of analysis, the emails sent with rapidmail contain a so-called tracking pixel, which connects to the rapidmail servers when the email is opened. In this way, it can be determined whether a newsletter message has been opened. We can also use rapidmail to determine whether and which links in the newsletter message have been clicked on. Optionally, links in the email can be set as tracking links, with which your clicks can be counted.
Legal basis: The legal basis for data processing is Art. 6 para. 1 lit. a) GDPR.
Recipient: The recipient of the data is rapidmail GmbH.
Transfer to third countries: Data will not be transferred to third countries.
Duration: The data stored by us as part of your consent for the purpose of the newsletter will be stored by us until you unsubscribe from the newsletter and deleted from both our servers and the servers of rapidmail after you unsubscribe from the newsletter. Data stored by us for other purposes (e.g. email addresses for the member area) remain unaffected by this.
Revocation option: You have the option of revoking your consent to data processing at any time with effect for the future. The legality of the data processing operations that have already taken place remains unaffected by the revocation.
Further data protection information: For more information, please refer to rapidmail's data security information at: https://www.rapidmail.de/datensicherheit .
For more information on the analysis functions of rapidmail, please see the following link: https://www.rapidmail.de/wissen-und-hilfe
This data protection declaration is based on the model data protection declaration of the law firm Weiß & Partner
Responsible for the content of this website is:
Optonic GmbH
Zollhallenstraße 11
79106 Freiburg
Germany
Phone +49 761 15436-0
info(at)optonic(dot)com
Optonic GmbH
Registered office: Freiburg i. Br.
District Court Freiburg i. Br. HRB 6038
VAT identification number. DE214104472
Managing Directors: Rainer Voigt, Johannes Schade
Webmaster: René Purwin
rene.purwin(at)optonic(dot)com
The copyright remains expressly reserved by Optonic GmbH. The commercial and business use of texts, images, and designs is not permitted and is subject to the copyright of Optonic GmbH.
Design / Art Direction: STARKAD
Code: Jonas Höscheler
Photography: Christian Hanner
Liability for Content
The content of our pages has been created with the utmost care. However, we cannot guarantee the accuracy, completeness, or timeliness of the content. As a service provider, we are responsible for our own content on these pages in accordance with general laws pursuant to Section 7 (1) of the German Telemedia Act (TMG). According to Sections 8 to 10 TMG, however, we are not obligated as a service provider to monitor transmitted or stored third-party information or to investigate circumstances that indicate illegal activity. Obligations to remove or block the use of information under general laws remain unaffected by this. Liability in this regard is, however, only possible from the time of knowledge of a specific legal violation. Upon becoming aware of such legal violations, we will remove this content immediately.
Liability for Links
Our website contains links to external third party websites, over whose content we have no control. Therefore, we cannot assume any liability for such external content. The respective provider or operator of the linked pages is always responsible for their content. The linked pages were checked for possible legal violations at the time of linking. Illegal content was not recognizable at the time of linking. However, permanent monitoring of the content of linked pages is not reasonable without concrete evidence of a legal violation. Upon becoming aware of any legal violations, we will remove such links immediately.
Copyright
The content and works created by the site operators on these pages are subject to German copyright law. The reproduction, editing, distribution, and any kind of use outside the limits of copyright law require the written consent of the respective author or creator. Downloads and copies of this site are permitted for private, non commercial use only. Insofar as the content on this site was not created by the operator, the copyrights of third parties are respected. In particular, third party content is identified as such. Should you nevertheless become aware of a copyright infringement, we request that you notify us accordingly. Upon becoming aware of any legal violations, we will remove such content immediately.
These include essential cookies that are necessary for the operation of the site, as well as others that are used only for anonymous statistical purposes, for comfort settings or to display personalized content. You can decide for yourself which categories you want to allow. Please note that based on your settings, not all functions of the website may be available.
Contents
I. Information about us as the controlling entity
II Rights of users and data subjects
III. Information on data processing
Contact enquiries / contact option
Online job applications / publication of job adverts
Website hosting www.optonic.com
General linking to profiles with third-party providers
YouTube on the Optonic website
It is possible to use our website without providing personal data. Different regulations may apply to the use of individual services on our website, which are explained separately below. Your personal data (e.g. name, address, email, telephone number, etc.) will only be processed by us in accordance with the provisions of the applicable data protection law (see below). In general, Optonic GmbH does not handle personal data. Data is personal if it can be clearly assigned to a specific natural person.
Personal data (hereinafter mostly referred to as ‘data’) is only processed by us to the extent necessary and for the purpose of providing a functional and user-friendly website, including its content and the services offered there.
According to Article 4(1) of Regulation (EU) 2016/679, i.e. the General Data Protection Regulation (hereinafter referred to as ‘GDPR’), ‘processing’ means any operation or set of operations which is performed on personal data or on sets of personal data, whether or not by automated means, such as collection, recording, organisation, structuring, storage, adaptation or alteration, retrieval, consultation, use, disclosure by transmission, dissemination or otherwise making available, alignment or combination, restriction, erasure or destruction.
With the following privacy policy, we provide information in particular about the type, scope, purpose, duration and legal basis of the processing of personal data, insofar as we decide either alone or together with others on the purposes and means of processing. In addition, we inform you below about the third-party components we use for optimisation purposes and to increase the quality of use, insofar as third parties process data on their own responsibility.
Our privacy policy is structured as follows
I. Information about us as the controller
II. rights of users and data subjects
III. Information on data processing
The responsible provider of this website in terms of data protection law is
Optonic GmbH
Represented by the managing directors:
Rainer Voigt, Johannes Schade, Rainer Voigt, sr.
Zollhallenstraße 11
79106 Freiburg im Breisgau
Phone: +49 761 15436-0
Email: info[AT]optonic.com
Contact person for data protection matters at Optonic GmbH:
René Purwin - Data Protection Coordinator
rene.purwin[AT]optonic.com
Optonic GmbH has appointed an independent, external data protection officer to monitor Optonic's compliance with the applicable laws and regulations on data protection (GDPR, European and German laws, BDSG). As a visitor to our website, you can contact the data protection officer if you have the impression that we are violating these laws and regulations or if you have any questions about our handling of personal data.
Contact details of the data protection officer:
PROLIANCE GmbH
Leopoldstr. 21
80802 Munich, Germany
datenschutzbeauftragter@datenschutzexperte.de
When contacting the data protection officer, please state the company to which your enquiry relates. Please refrain from enclosing sensitive information such as a copy of your ID with your enquiry.
With regard to the data processing described in more detail below, users and data subjects have the right
In addition, the provider is obliged to inform all recipients to whom data has been disclosed by the provider of any correction or deletion of data or the restriction of processing that takes place on the basis of Articles 16, 17 para. 1, 18 GDPR. However, this obligation does not apply if this notification is impossible or involves a disproportionate effort. Notwithstanding this, the user has a right to information about these recipients.
Users and data subjects also have the right to object to the future processing of data concerning them in accordance with Art. 21 GDPR, provided that the data is processed by the provider in accordance with Art. 6 para. 1 lit. f) GDPR. In particular, an objection to data processing for the purpose of direct advertising is permitted.
Your data processed when using our website will be deleted or blocked as soon as the purpose of storage no longer applies, the deletion of the data does not conflict with any statutory retention obligations and no other information is provided below on individual processing methods.
The provider (Strato AG, see below) uses a cookie manager to obtain consent for the use of technically unnecessary cookies on the website.
When the website is accessed, a cookie with the settings information is stored on the user's end device so that the query regarding consent does not have to be made on a subsequent visit.
The cookie is required to obtain the user's legally compliant consent.
The user can prevent or stop the installation of cookies by changing the settings in their browser.
a) Session cookies/session cookies
We use so-called cookies on our website. Cookies are small text files or other storage technologies that are placed and stored on your end device by the Internet browser you use. These cookies are used to process certain information from you, such as your browser or location data or your IP address, on an individual basis.
This processing makes our website more user-friendly, effective and secure, as the processing enables, for example, the reproduction of our website in different languages or the offer of a shopping basket function.
The legal basis for this processing is Art. 6 para. 1 lit. b) GDPR, insofar as these cookies process data for contract initiation or contract fulfilment.
If the processing does not serve to initiate or fulfil a contract, our legitimate interest lies in improving the functionality of our website. The legal basis in this case is Art. 6 para. 1 lit. f) GDPR.
These session cookies are deleted when you close your Internet browser.
b) Third-party cookies
Our website may also use cookies from partner companies with whom we work for the purposes of advertising, analysing or the functionalities of our website.
Please refer to the following information for details, in particular the purposes and legal basis for processing such third-party cookies.
c) Removal option
You can prevent or restrict the installation of cookies by changing the settings of your Internet browser. You can also delete cookies that have already been saved at any time. However, the steps and measures required for this depend on the specific Internet browser you are using. If you have any questions, please use the help function or documentation of your Internet browser or contact its manufacturer or support. In the case of so-called Flash cookies, however, processing cannot be prevented via the browser settings. Instead, you must change the settings of your Flash player. The steps and measures required for this also depend on the specific Flash player you are using. If you have any questions, please also use the help function or documentation of your Flash player or contact the manufacturer or user support. For security reasons, we advise against using a Flash player.
However, if you prevent or restrict the installation of cookies, this may mean that not all functions of our website can be used to their full extent.
If you contact us via contact form or email, the data you provide will be used to process your enquiry. The provision of the data is necessary for processing and answering your enquiry - without it we cannot answer your enquiry or can only answer it to a limited extent.
The legal basis for this processing is Art. 6 para. 1 lit. b) GDPR.
Your data will be deleted if your enquiry has been conclusively answered and the deletion does not conflict with any statutory retention obligations, such as in the case of any subsequent contract processing.
If you register for our free newsletter, the data requested from you for this purpose, i.e. your email address and - optionally - your name and address, will be transmitted to us. At the same time, we store the IP address of the Internet connection from which you access our website as well as the date and time of your registration. As part of the further registration process, we will obtain your consent to send you the newsletter, describe the content in detail and refer you to this privacy policy. We use the data collected in this process exclusively for sending the newsletter - in particular, it is therefore not passed on to third parties.
The legal basis for this is Art. 6 para. 1 lit. a) GDPR.
You can revoke your consent to receive the newsletter at any time with effect for the future in accordance with Art. 7 para. 3 GDPR. All you have to do is, inform us of your cancellation or click on the unsubscribe link contained in every newsletter.
We offer you the opportunity to apply for a job with us via our website. For these digital applications, we collect and process your applicant and application data electronically to handle the application process.
The legal basis for this processing is Section 26 (1) sentence 1 BDSG in conjunction with Art. 88 (1) GDPR. Art. 88 para. 1 GDPR.
If an employment contract is concluded after the application procedure, we will store the data you submitted during the application in your personnel file for the purpose of the usual organisational and administrative process - of course in compliance with further legal obligations.
The legal basis for this processing is also Section 26 para. 1 sentence 1 BDSG in conjunction with Art. 88 para. 1 GDPR. Art. 88 para. 1 GDPR.
If an application is rejected, we automatically delete the data transmitted to us within a maximum of two months after notification of the rejection. However, the data will not be deleted if the data requires longer storage of up to four months or until the conclusion of legal proceedings due to legal provisions, e.g. due to the burden of proof under the AGG.
In this case, the legal basis is Art. 6 para. 1 lit. f) GDPR and Section 24 para. 1 no. 2 BDSG. Our legitimate interest lies in legal defence or enforcement.
If you expressly consent to your data being stored for a longer period of time, e.g. for your inclusion in a database of applicants or interested parties, the data will be processed further on the basis of your consent. The legal basis is then Art. 6 para. 1 lit. a) GDPR. However, you can of course revoke your consent at any time in accordance with Art. 7 para. 3 GDPR by making a declaration to us with effect for the future.
For technical reasons, in particular to ensure a secure and stable Internet presence, data is transmitted to us or to our web space provider by your Internet browser. With these so-called server log files, the type and version of your Internet browser, the operating system, the website from which you have switched to our Internet presence (referrer URL), the website(s) of our Internet presence that you visit, the date and time of the respective access and the IP address of the Internet connection from which our Internet presence is used are collected, among other things.
The data collected in this way is stored temporarily, but not together with other data about you.
This storage takes place on the legal basis of Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the improvement, stability, functionality and security of our website.
The data will be deleted after seven days at the latest, unless further storage is required for evidence purposes. Otherwise, the data is excluded from deletion in whole or in part until an incident has been finally clarified.
This website is hosted by the German provider Strato. Strato AG is a processor within the meaning of Art. 28 of the GDPR and has concluded a corresponding ‘order processing contract’ (AVV) with us: https://www.strato.de/agb/avv/
Contact Strato: https://www.strato.de/impressum/
Strato AG, Otto-Ostrowski-Str. 7, 10249 Berlin, Germany
Strato hosts all websites, including ours, exclusively on web servers in Germany, so that the GDPR applies without restriction. Details on the handling of personal data can be found in Strato AG's privacy policy: https://www.strato.de/datenschutz/
The legal basis for data processing by Strato AG results from Art. 6 I lit. a GDPR and further paragraphs of the GDPR.
The data transmitted by you to utilise our range of goods and/or services is processed by us for the purpose of contract processing and is required in this respect. Conclusion and fulfilment of the contract are not possible without the provision of your data.
The legal basis for the processing is Art. 6 para. 1 lit. b) GDPR.
We delete the data once the contract has been fully processed, but must observe the retention periods under tax and commercial law.
As part of the contract processing, we pass on your data to the transport company commissioned with the delivery of goods or to the financial service provider, insofar as the transfer is necessary for the delivery of goods or for payment purposes.
The legal basis for the transfer of data is then Art. 6 para. 1 lit. b) GDPR.
We maintain an online presence on LinkedIn to present our company and our services and to communicate with customers/prospects. LinkedIn is a service of LinkedIn Ireland Unlimited Company, Wilton Plaza, Wilton Place, Dublin 2, Ireland, a subsidiary of LinkedIn Corporation, 1000 W. Maude Avenue, Sunnyvale, CA 94085, USA.
In this respect, we would like to point out that there is a possibility that user data may be processed outside the European Union, in particular in the USA. This may result in increased risks for users in that, for example, subsequent access to user data may be made more difficult. We also have no access to this user data. The access option lies exclusively with LinkedIn.
You can find LinkedIn's privacy policy at
https://www.linkedin.com/legal/privacy-policy
We maintain an online presence on YouTube to present our company and our services and to communicate with customers/prospects. YouTube is a service of Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, a subsidiary of Google LLC, 1600 Amphitheatre Parkway, Mountain View, CA 94043 USA.
In this respect, we would like to point out that there is a possibility that user data may be processed outside the European Union, in particular in the USA. This may result in increased risks for users in that, for example, subsequent access to user data may be made more difficult. We also have no access to this user data. The access option lies exclusively with YouTube.
You can find YouTube's privacy policy at
https://policies.google.com/privacy
The provider uses a link on the website to the social networks listed below.
The legal basis for this is Art. 6 para. 1 lit. f GDPR. The provider has a legitimate interest in improving the quality of use of the website.
The plugins are integrated via a linked graphic. Only by clicking on the corresponding graphic is the user redirected to the service of the respective social network.
Once the customer has been redirected, the respective network collects information about the user. This is initially data such as IP address, date, time and page visited. If the user is logged into their user account on the respective network during this time, the network operator may be able to assign the information collected about the user's specific visit to the user's personal account. If the user interacts via a ‘Share’ button of the respective network, this information can be stored in the user's personal user account and published if necessary. If the user wants to prevent the collected information from being directly assigned to their user account, the user must log out before clicking on the graphic. It is also possible to configure the respective user account accordingly.
The following social networks are linked by the provider:
We use Google Analytics on our website. This is a web analysis service provided by Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as ‘Google’.
The Google Analytics service is used to analyse the usage behaviour of our website. The legal basis is Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the analysis, optimisation and economic operation of our website.
Usage and user-related information, such as IP address, location, time or frequency of visits to our website, is transmitted to a Google server in the USA and stored there. However, we use Google Analytics with the so-called anonymisation function. This function allows Google to truncate the IP address within the EU or EEA.
The data collected in this way is in turn used by Google to provide us with an analysis of the visit to our website and the usage activities there. This data can also be used to provide other services related to the use of our website and the use of the Internet.
Google states that it will not associate your IP address with any other data. In addition, Google keeps under:
https://www.google.com/intl/de/policies/privacy/partners
provides further data protection information for you, for example on the options for preventing the use of data.
In addition, Google offers at
https://tools.google.com/dlpage/gaoptout?hl=de
a so-called deactivation add-on along with further information on this. This add-on can be installed with the most common Internet browsers and offers you further control over the data that Google collects when you visit our website. The add-on informs the JavaScript (ga.js) of Google Analytics that information about your visit to our website should not be transmitted to Google Analytics. However, this does not prevent information from being transmitted to us or to other web analysis services. You can of course also find out whether and which other web analysis services we use in this privacy policy.
We use Google Maps on our website to display our location and to provide directions. This is a service provided by Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as ‘Google’.
In order to enable the display of certain fonts on our website, a connection to the Google server in the USA is established when our website is accessed.
If you call up the Google Maps component integrated into our website, Google stores a cookie on your end device via your Internet browser. Your user settings and data are processed in order to display our location and provide directions. We cannot rule out the possibility that Google uses servers in the USA.
If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in optimising the functionality of our website.
The connection to Google established in this way enables Google to determine from which website your enquiry has been sent and to which IP address the directions are to be transmitted.
If you do not agree to this processing, you have the option of preventing the installation of cookies by making the appropriate settings in your Internet browser. Details on this can be found above under ‘Cookies’.
In addition, the use of Google Maps and the information obtained via Google Maps is governed by the Google Terms of Use https://policies.google.com/terms?gl=DE&hl=de and the Terms and Conditions for Google Maps https://www.google.com/intl/de_de/help/terms_maps.html.
In addition, Google offers at
https://adssettings.google.com/authenticated
https://policies.google.com/privacy
for further information.
We use “Vimeo” on our website to display videos. This is a service provided by Vimeo, LL C, 555 West 18 th Street, New York, New York 10011, USA, hereinafter referred to as “Vimeo”.
Some of the user data is processed on Vimeo servers in the USA.
If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in improving the quality of our website.
If you visit a page of our website in which a video is embedded, a connection to the Vimeo servers in the USA is established to display the video. For technical reasons, it is necessary for Vimeo to process your IP address. In addition, the date and time of your visit to our website are also recorded.
If you are logged in to Vimeo at the same time as you visit one of our websites in which a Vimeo video is embedded, Vimeo may assign the information collected in this way to your personal user account there. If you wish to prevent this, you must either log out of Vimeo before visiting our website or configure your Vimeo user account accordingly.
Vimeo uses the web analysis service Google Analytics for the purpose of functionality and usage analysis. Google Analytics stores cookies on your end device via your Internet browser and sends information about the use of our Internet pages in which a Vimeo video is embedded to Google. It cannot be ruled out that Google will process this information in the USA.
If you do not agree to this processing, you have the option of preventing the installation of cookies by making the appropriate settings in your Internet browser. Details on this can be found above under “Cookies”.
The legal basis is Art. 6 para. 1 lit. f) GDPR. Our legitimate interest lies in the quality improvement of our website and in the legitimate interest of Vimeo to statistically analyze user behavior for optimization and marketing purposes.
Vimeo offers under
for further information on the collection and use of data and on your rights and options for protecting your privacy.
We use YouTube on our website. This is a video portal of Google Ireland Limited, Gordon House, Barrow Street, Dublin 4, Ireland, hereinafter referred to as “YouTube”.
We use YouTube in connection with the “extended data protection mode” function in order to be able to show you videos. If you have given your consent for this processing, the legal basis is Art. 6 para. 1 lit. a GDPR. The legal basis may also be Art. 6 para. 1 lit. f GDPR. Our legitimate interest lies in improving the quality of our website. According to YouTube, the “Enhanced Privacy Mode” function means that the data described in more detail below is only transmitted to the YouTube server when you actually start a video.
Without this “extended data protection mode”, a connection to the YouTube server in the USA is established as soon as you access one of our web pages on which a YouTube video is embedded.
This connection is necessary in order to be able to display the respective video on our website via your Internet browser. In the course of this, YouTube will at least record and process your IP address, the date and time and the website you have visited. In addition, a connection is established to Google's “DoubleClick” advertising network.
If you are logged in to YouTube at the same time, YouTube will assign the connection information to your YouTube account. If you wish to prevent this, you must either log out of YouTube before visiting our website or make the appropriate settings in your YouTube user account.
For the purpose of functionality and analysis of user behavior, YouTube permanently stores cookies on your end device via your Internet browser. If you do not agree to this processing, you have the option of preventing the storage of cookies by changing the settings in your Internet browser. You can find more information on this above under “Cookies”.
Google provides further information about the collection and use of data as well as your rights and protection options in this regard in the privacy policy available at
https://policies.google.com/privacy
If you subscribe to our company's newsletter, the data in the respective input mask will be transmitted to the controller. Subscription to our newsletter takes place in a so-called double opt-in procedure. This means that after registering, you will receive an email asking you to confirm your registration. This confirmation is necessary so that no-one can register with other people's email addresses. When registering for the newsletter, the user's IP address and the date and time of registration are stored. This serves to prevent misuse of the services or the email address of the person concerned. The data is not passed on to third parties. An exception is made if there is a legal obligation to pass on the data. The data is used exclusively for sending the newsletter. Subscription to the newsletter can be terminated by the data subject at any time. Consent to the storage of personal data can also be revoked at any time. There is a corresponding link for this purpose in every newsletter. The legal basis for the processing of data after registration for the newsletter by the user is Art. 6 para. 1 lit. a) GDPR if the user has given consent. The legal basis for sending the newsletter as a result of the sale of goods or services is Section 7 (3) UWG
Description and purpose: We use rapidmail to send newsletters. The provider is rapidmail GmbH, Wentzingerstraße 21, 79106 Freiburg, Germany. Among other things, rapidmail is used to organize and analyse the sending of newsletters. The data you enter for the purpose of subscribing to the newsletter is stored on rapidmail's servers in Germany. If you do not wish to be analyzed by rapidmail, you must unsubscribe from the newsletter. For this purpose, we provide a corresponding link in every newsletter message. For the purpose of analysis, the emails sent with rapidmail contain a so-called tracking pixel, which connects to the rapidmail servers when the email is opened. In this way, it can be determined whether a newsletter message has been opened. We can also use rapidmail to determine whether and which links in the newsletter message have been clicked on. Optionally, links in the email can be set as tracking links, with which your clicks can be counted.
Legal basis: The legal basis for data processing is Art. 6 para. 1 lit. a) GDPR.
Recipient: The recipient of the data is rapidmail GmbH.
Transfer to third countries: Data will not be transferred to third countries.
Duration: The data stored by us as part of your consent for the purpose of the newsletter will be stored by us until you unsubscribe from the newsletter and deleted from both our servers and the servers of rapidmail after you unsubscribe from the newsletter. Data stored by us for other purposes (e.g. email addresses for the member area) remain unaffected by this.
Revocation option: You have the option of revoking your consent to data processing at any time with effect for the future. The legality of the data processing operations that have already taken place remains unaffected by the revocation.
Further data protection information: For more information, please refer to rapidmail's data security information at: https://www.rapidmail.de/datensicherheit .
For more information on the analysis functions of rapidmail, please see the following link: https://www.rapidmail.de/wissen-und-hilfe
This data protection declaration is based on the model data protection declaration of the law firm Weiß & Partner
Responsible for the content of this website is:
Optonic GmbH
Zollhallenstraße 11
79106 Freiburg
Germany
Phone +49 761 15436-0
info(at)optonic(dot)com
Optonic GmbH
Registered office: Freiburg i. Br.
District Court Freiburg i. Br. HRB 6038
VAT identification number. DE214104472
Managing Directors: Rainer Voigt, Johannes Schade
Webmaster: René Purwin
rene.purwin(at)optonic(dot)com
The copyright remains expressly reserved by Optonic GmbH. The commercial and business use of texts, images, and designs is not permitted and is subject to the copyright of Optonic GmbH.
Design / Art Direction: STARKAD
Code: Jonas Höscheler
Photography: Christian Hanner
Liability for Content
The content of our pages has been created with the utmost care. However, we cannot guarantee the accuracy, completeness, or timeliness of the content. As a service provider, we are responsible for our own content on these pages in accordance with general laws pursuant to Section 7 (1) of the German Telemedia Act (TMG). According to Sections 8 to 10 TMG, however, we are not obligated as a service provider to monitor transmitted or stored third-party information or to investigate circumstances that indicate illegal activity. Obligations to remove or block the use of information under general laws remain unaffected by this. Liability in this regard is, however, only possible from the time of knowledge of a specific legal violation. Upon becoming aware of such legal violations, we will remove this content immediately.
Liability for Links
Our website contains links to external third party websites, over whose content we have no control. Therefore, we cannot assume any liability for such external content. The respective provider or operator of the linked pages is always responsible for their content. The linked pages were checked for possible legal violations at the time of linking. Illegal content was not recognizable at the time of linking. However, permanent monitoring of the content of linked pages is not reasonable without concrete evidence of a legal violation. Upon becoming aware of any legal violations, we will remove such links immediately.
Copyright
The content and works created by the site operators on these pages are subject to German copyright law. The reproduction, editing, distribution, and any kind of use outside the limits of copyright law require the written consent of the respective author or creator. Downloads and copies of this site are permitted for private, non commercial use only. Insofar as the content on this site was not created by the operator, the copyrights of third parties are respected. In particular, third party content is identified as such. Should you nevertheless become aware of a copyright infringement, we request that you notify us accordingly. Upon becoming aware of any legal violations, we will remove such content immediately.
To load this element, it is required to consent to the following cookie category: {category}.




